

Vraag van een cursist: Hoe groot is mijn datamodel?
Vraag naar aanleiding van onze nazorgservice
Deelnemers aan onze trainingen kunnen gebruikmaken van onze nazorgservice. Heeft een cursist na afloop van een training nog vragen over de behandelde stof? Dan staan onze trainers klaar om te helpen. Veel deelnemers maken hier gebruik van. Soms zijn deze vragen en antwoorden ook waardevol voor anderen. Daarom delen we ze graag, zodat iedereen ervan kan profiteren.
Dataset te groot voor Power BI Pro
Hieronder vind je een vraag van een deelnemer die onlangs een incompany Power BI-training heeft gevolgd:
“Onze dataset is te groot voor Power BI Pro. Waar kan ik zien waardoor dit komt?”
Onderstaand vind je het antwoord en de oplossing.
Waarom deze vraag?
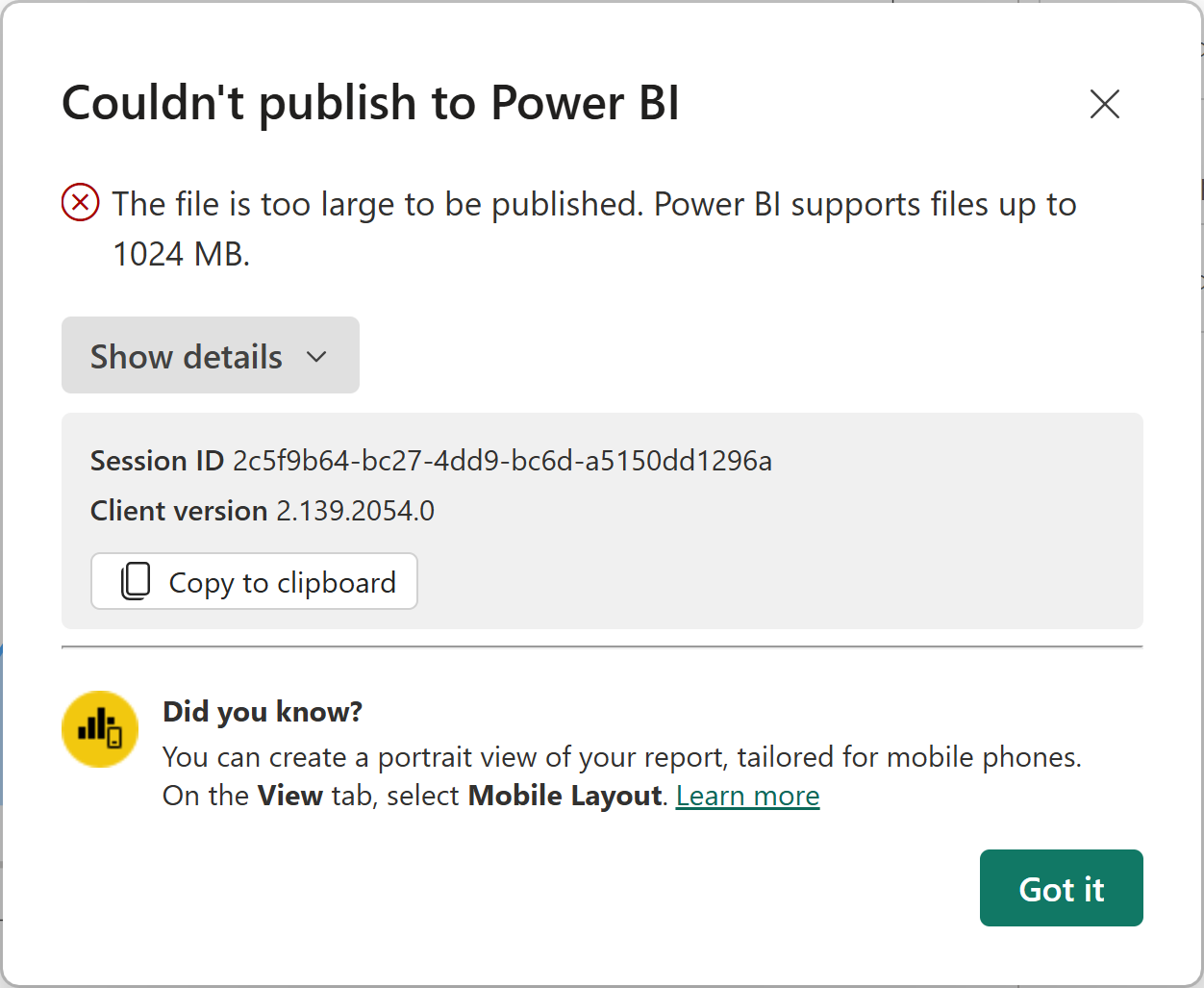
Een van de semantische modellen van de deelnemer was aanzienlijk gegroeid. Wat binnen de organisatie voor de nodige stress zorgde. De externe beheerder stelde voor om Premium per User-licenties aan te schaffen, wat aanzienlijke kosten met zich mee zou brengen. Hierover bestond echter twijfel, aangezien het Power BI-bestand (PBIX) ‘slechts’ 700 MB groot was—nog altijd binnen de 1 GB-limiet die een Power BI Pro-licentie toestaat voor publicatie.
De grootte van een datamodel is van invloed op je Power BI licentie en prestaties
De grootte van je semantische model speelt altijd een cruciale rol, zelfs als het binnen de grenzen van je Power BI licentie valt. Dit heeft niet alleen invloed op de prestaties van gekoppelde Power BI-rapporten, maar ook op de licentievereisten binnen Power BI.
Vooral bij grotere organisaties die Microsoft Fabric gebruiken, is dit extra belangrijk. Daar heeft de omvang van datamodellen direct impact op het aantal verbruikte Capaciteitseenheden (CU’s). Een belangrijke grens is 1 GB. Want bij een Power BI Pro-licentie mag een dataset deze limiet niet overschrijden.
Is de dataset groter? Dan is een Premium per User-licentie een mogelijke oplossing. Maar dit brengt ook hogere kosten met zich mee. Het is echter essentieel om eerst te bepalen of dit daadwerkelijk de beste keuze is. Je moet dus eerst zeker weten hoe groot je semantische model is en kijken of die niet (nog meer) geoptimaliseerd kan worden.
Hoe weet je wat de grootte is van je model?
Een Power BI Desktop-bestand wordt meestal opgeslagen in het PBIX-formaat. Dit bestand bevat niet alleen een semantisch model, maar ook alle visualisaties, afbeeldingen en pagina’s.
Bij het opslaan van een PBIX bestand past Power BI Desktop een sterke compressie toe. Het bestand is dus kleiner, dan het werkelijke model dat er inzit.
Helaas biedt Power BI Desktop geen manier om de omvang van het model te tonen. Om dit op te meten heb je een extern programma nodig, bijvoorbeeld DAX studio.
Uitgewerkt voorbeeld met behulp van DAX Studio
Ik heb vanaf de website van het RDW een bestand gedownload van alle voertuigen met kentekens in Nederland. Dit is een enorm CSV bestand. Met dit bestand heb ik een Power BI-datamodel gemaakt. Er is (nog) niets uitgefilterd. Zoals hier hieronder te zien is, is het oorspronkelijke CSV bestand 10,6 GB. Terwijl het Power BI bestand met dezelfde data ‘maar’ 598 MB is.

In DAX studio zien we dat het datamodel weer groter is dan het PBIX bestand (1,19 GB).
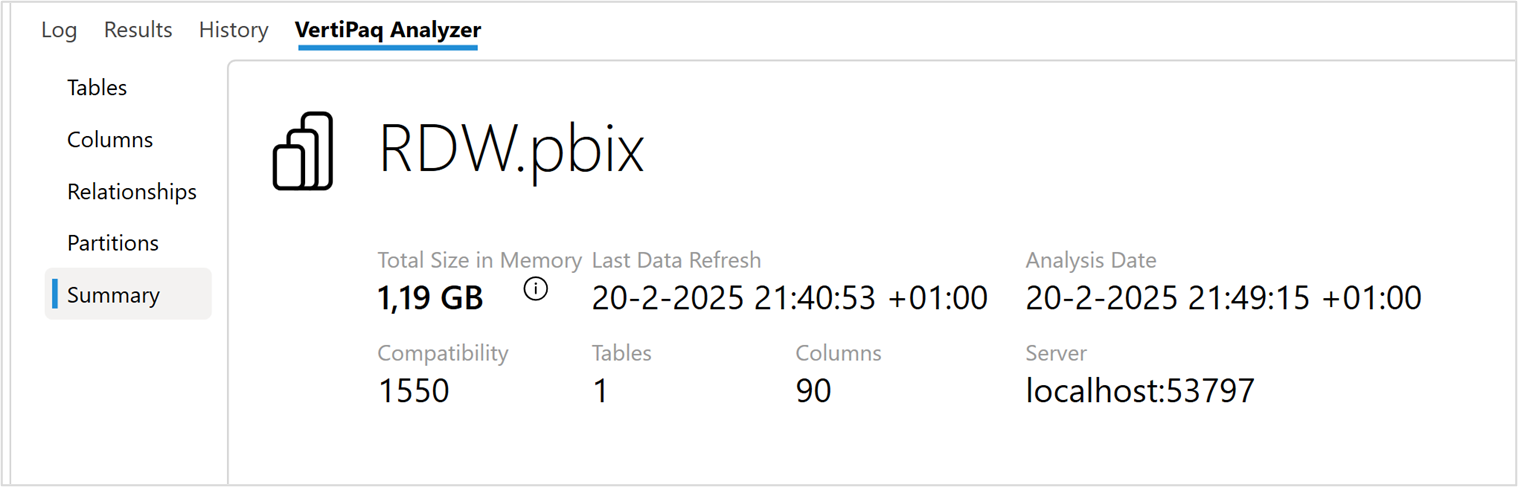
Dit model is dus (nu nog) te groot om met een Power BI Pro licentie te gebruiken. In het “Tables” menu in DAX Studio, zie onderstaande afbeelding, kan je gedetailleerd zien wat de omvang is van de verschillende kolommen en tabellen. Aan de hand van onderstaande gegevens in DAX Studio kun je proberen het model verder te optimaliseren.
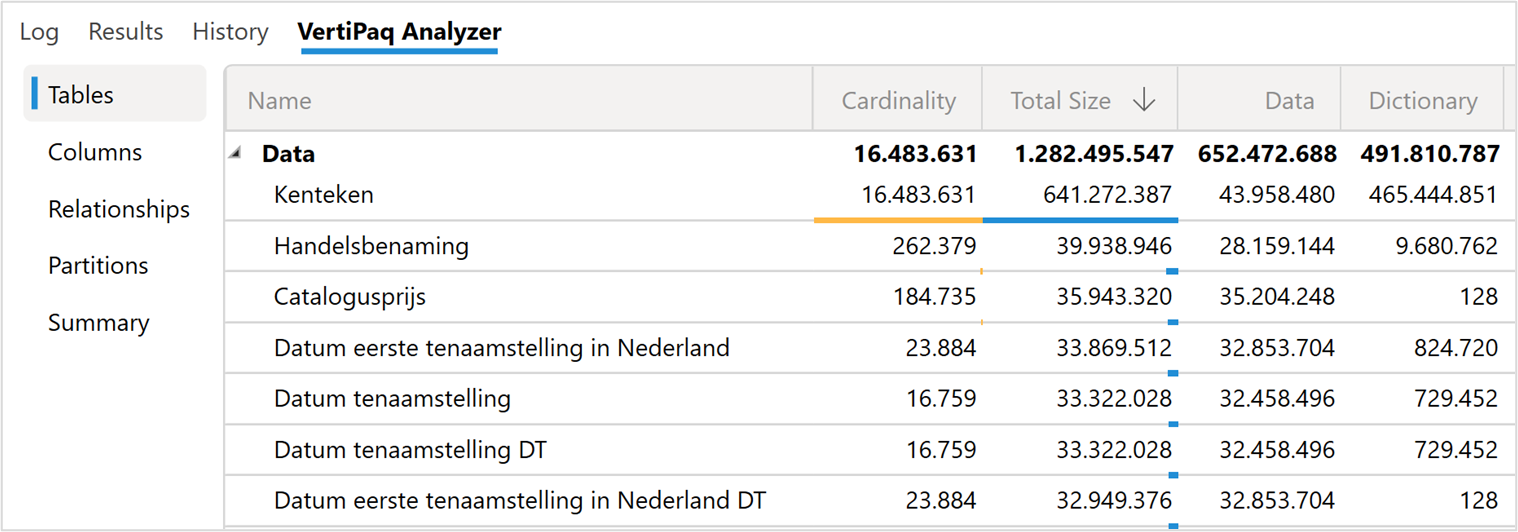
Belangrijk: de Cardinality van de kolommen
Een belangrijk gegeven hier is de ‘Cardinality’ van de kolommen (zie de printscreen van DAX Studio). Power BI gebruikt een zogenaamde “column store” database. Bij zo’n database wordt iedere kolom afzonderlijk gecomprimeerd. Hierdoor kunnen er snelle query’s op de data plaatsvinden, terwijl de data ook sterk verkleind wordt.
De belangrijkste factor die bepaald hoe efficiënt de Power BI database dit kan doen is de ‘Cardinality’.
Cardinality staat voor het aantal verschillende waardes in een kolom. Een kolom met 16 miljoen rijen waarin “ja” of “nee” staat, kan veel efficiënter gecomprimeerd worden dan een kolom met 16 miljoen verschillende kentekens. Daarom is de ‘Kenteken’ kolom (zie de afbeelding) hier ook met afstand de grootste kolom.
De oplossing voor de klant
Toen we het Power BI bestand van de deelnemer verbonden met DAX studio, zoals in bovenstaand voorbeeld, zagen we snel wat er aan de hand was. Het model was 1.1 GB, maar:
- Er waren veel verborgen datumtabellen die een erg hoge ‘cardinality’ hadden
- In de datumtabel die met DAX gemaakt was, was de ‘cardinality’ zelf meer dan 500.000. Dat is extreem want een jaar kan nooit meer dat 366 datums bevatten
We ontdekten 3 grote fouten die zorgden voor extreme groei van dit model. Deze waren gelukkig eenvoudig op te lossen. Onderstaand de 3 grote gevonden fouten:
- Er zaten invoerfouten in bepaalde datumkolommen. Waardoor de oudste datum ruim 1400 jaar geleden was
- De auto date/time optie stond nog aan bij. Door dit verkeerde vinkje werd het model ruim 300 MB groter
- De datumtabel die met DAX gemaakt werd gebruikte de CALENDARAUTO() functie. Die door de invoerfouten ruim 1400 jaar aan datums weergaf
Het oplossen van bovenstaande fouten maakten de dataset al 500 MB kleiner. Verder ontdekte de cursist een groot aantal onnodige kolommen met hoge ‘cardinality’. Binnen een half uur was het model verkleind tot onder de 500 MB. En met de tips die de cursist verder kreeg kon hij het zelfstandig nog verder verkleinen.
Conclusie:
De grootte van Power BI-semantische modellen is cruciaal voor zowel de prestaties als de kosten. Zelfs kleine fouten kunnen grote gevolgen hebben en leiden tot onnodige Power BI-licenties met hogere kosten. Optimalisatie begint met een nauwkeurige meting van je datamodel. Hiervoor is een externe tool zoals DAX Studio, Tabular Editor of Measurekiller onmisbaar.




 Print dit artikel
Print dit artikel